Yesterday, Silicon Valley trade publication The Information launched TITV, a live-streaming news program. For its first episode, the company’s founder Jessica Lessin interviewed Mark Zuckerberg about his recent attempts to hire AI executives away from other companies for huge sums of money.
It is impossible to say what actually happened in the interview, however, because there were audio problems with the livestream—the Zuckerberg segment was completely silent, giving us a minute and 50 seconds of video of Zuckerberg’s face moving with no sound coming out.
In recent weeks, however, Zuckerberg has really ramped up his rhetoric about “superintelligence,” throwing hundreds of millions of dollars at AI researchers in attempts to hire them at Meta, and beginning work on massive data centers around the country to power his AI. Zuckerberg and Meta have talked endlessly about AI as a game changer, while being unable or unwilling to keep AI-generated misinformation and slop off of Meta platforms.
Meanwhile, there has been increased discussion about the possible power of using AI for journalism, which we have written about extensively. I saw the silent interview with Zuckerberg as both an opportunity to check out the awesome abilities of Meta’s AI, and to test AI tools at a task some of them are supposedly good at—reading lips. If these technologies worked as well as their creators have promised, it might be possible to provide the world with information from The Lost Mark Zuckerberg Interview.
Here is how my experiment went.
Because Zuckerberg was obviously talking about Meta AI, I thought I would try his tool first. I took video from the interview and asked Meta AI to lip read it to tell me what they were saying:
“I’d love to help! However, I’m a text-based AI and don’t have capability to visually lip read videos,” Meta AI said. It then suggested that I “find a professional lip reader or transcription service that specializes in lip reading videos” or “use automated lip reading software.”
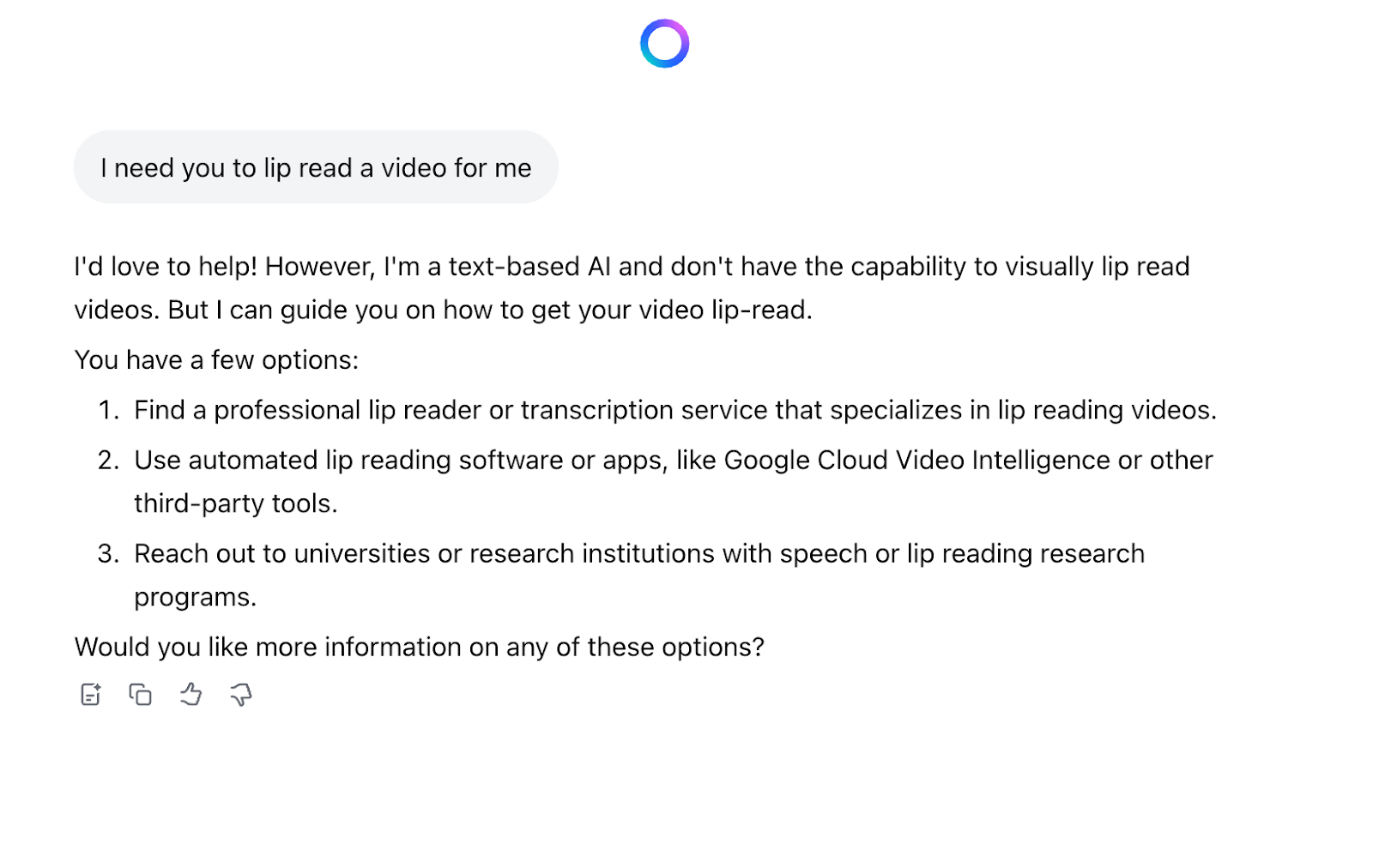
I then tried to upload still images to see if Meta AI could parse them:
When I uploaded additional images, Meta AI was also not able to provide any information about what was being said.
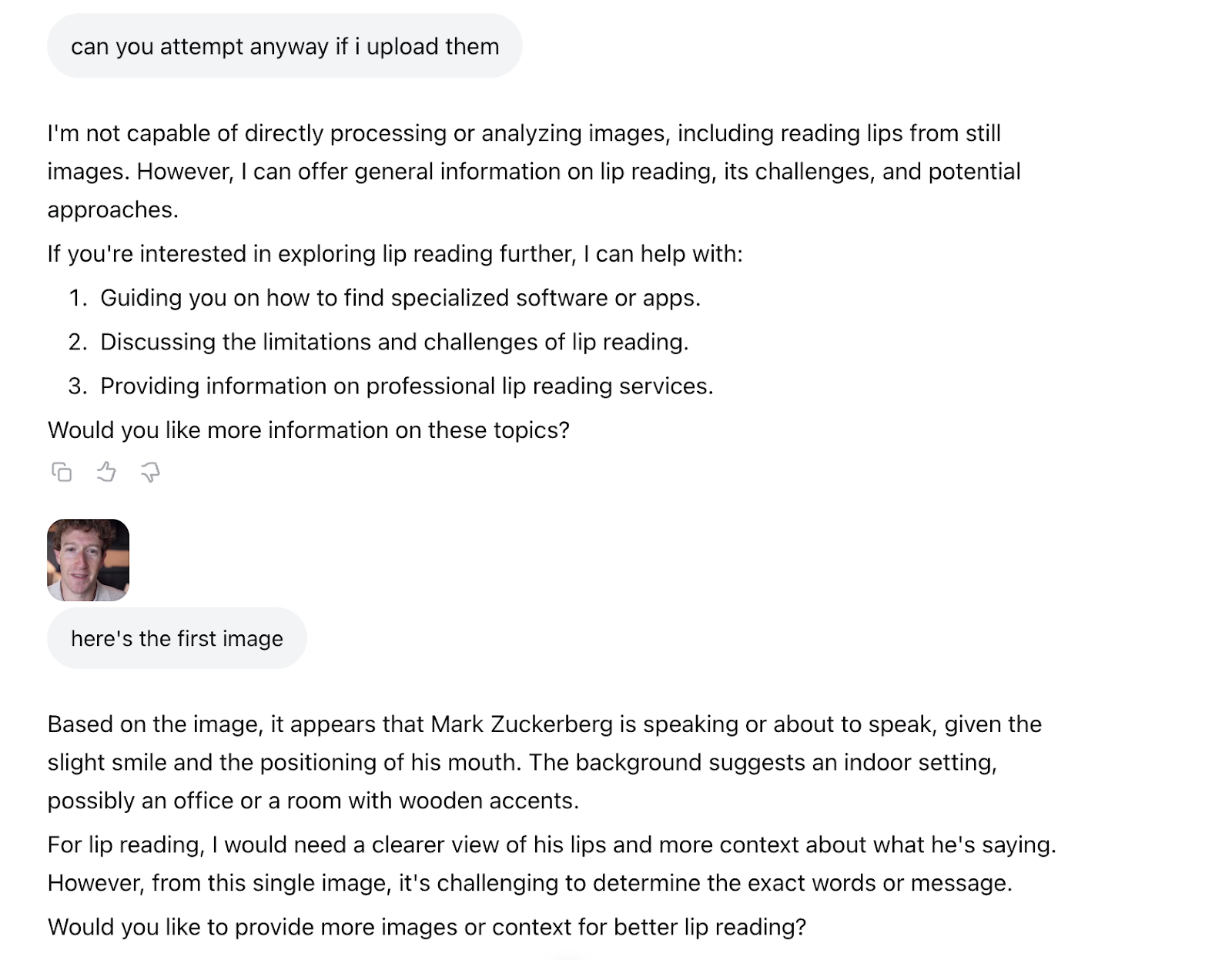
I then went to ChatGPT, because Zuckerberg is reportedly offering pay packages of up to $300 million to OpenAI staffers to come work at Meta. I uploaded the 1:50 video and ChatGPT told me “the video processing took too long and timed out.” I then uploaded a 25 second clip and it told me “the system is still timing out while trying to extract frames.” I then asked it to do the first five seconds and it said “even with the shorter clip and smaller scope (first 5 seconds), the system timed out.” I then asked for it to extract one single frame, and it said “it looks like the system is currently unable to extract even a single frame from the video file.” ChatGPT then asked me to take a screenshot of Zuckerberg. I sent it this:

And ChatGPT said “the person appears to be producing a sound like ‘f’ or ‘v’ (as in ‘video’ or ‘very’),” but that “possibly ‘m’ or ‘b,’ depending on the next motion.” I then shared the 10 frames around that single screenshot, and ChatGPT said “after closely analyzing the progression of lip shapes and facial motion,” the “probable lip-read phrase” was “This is version.” I then uploaded 10 more frames and it said the “full phrase so far (high confidence): ‘This version is just.’”
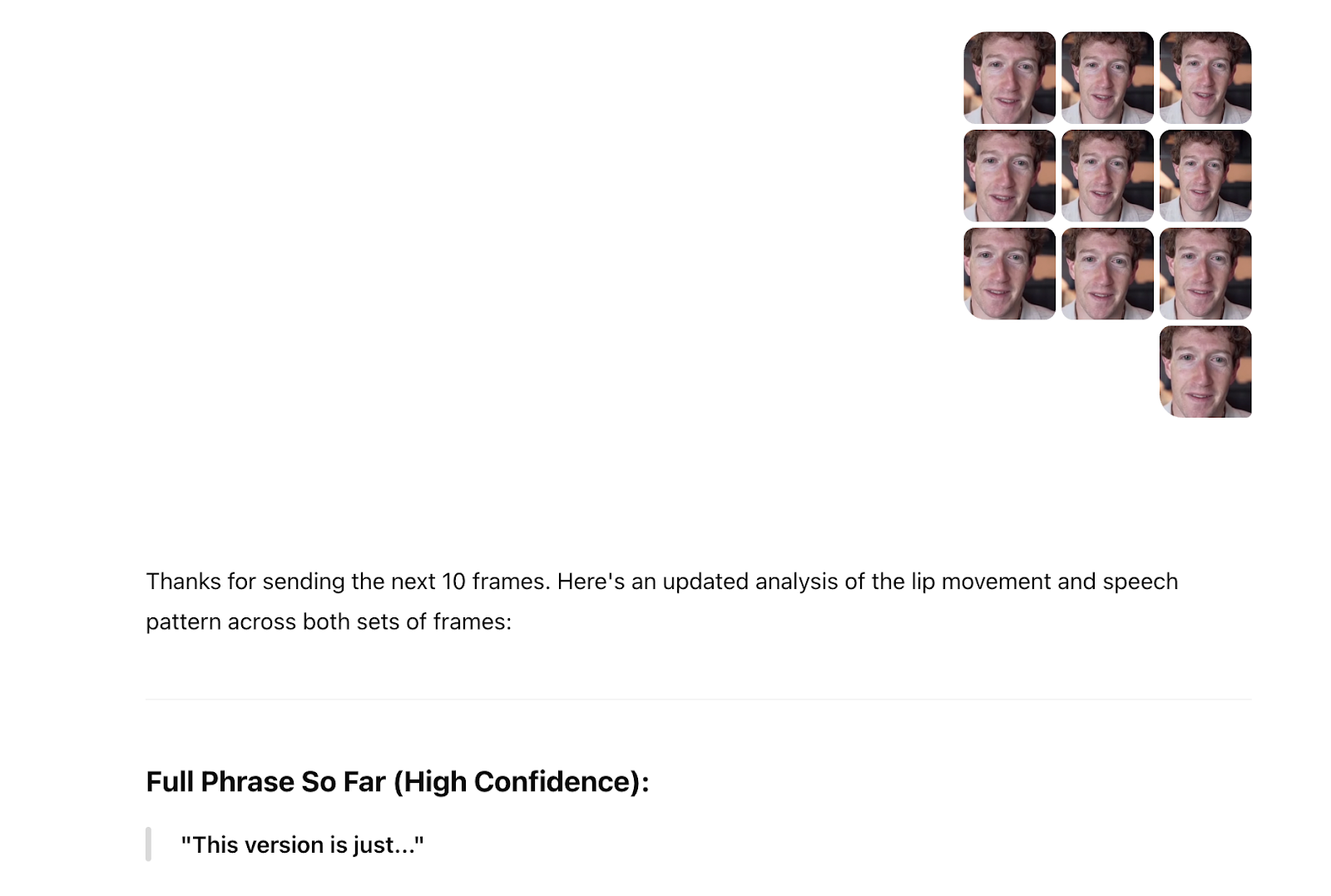









I then decided to try to extract every frame from the video and upload it to ChatGPT.
I went to a website called frame-extractor.com and cut the video into 3,000 frames. After it had processed 700 of them, I tried to upload them to ChatGPT and it did not work. I then decided I would go 10 frames at a time from the beginning of the clip. Even though I sent an entirely different portion of the video and told ChatGPT we were starting from a different part of the video, it still said that the beginning of the video said “this version is.” I continued uploading frames, 10 at a time. These frames included both Lessin and Zuckerberg, not just Zuckerberg.
ChatGPT slowly began to create a surely accurate transcript of the lost audio of this interview: “This version is just that it we built,” ChatGPT said. As I added more and more frames, it refined the answer: “This version is what we’re going to do,” it said. Finally, it seemed to make a breakthrough. “Is this version of LLaMA more powerful than the one we released last year?” the ChatGPT transcript said. It was not clear about who was speaking, however. ChatGPT said "her mouth movements," but then explained that the "speaker is the man on the left" (Lessin, not Zuckerberg, was speaking in these frames).
I had uploaded 40 of a total of 3,000 frames. Zoom video is usually 30 fps, so in approximately 1.5 seconds, Lessin and/or Zuckerberg apparently said “Is this version of LLaMA more powerful than the one we released last year?” I then recorded this phrase at a normal speaking speed, and it took about four seconds. Just a data point.


 Lipreadtest0:00/4.9733331×
Lipreadtest0:00/4.9733331×
I then got an error message from ChatGPT, and got rate-limited because I was uploading too much data. It told me that I needed to wait three hours to try again.
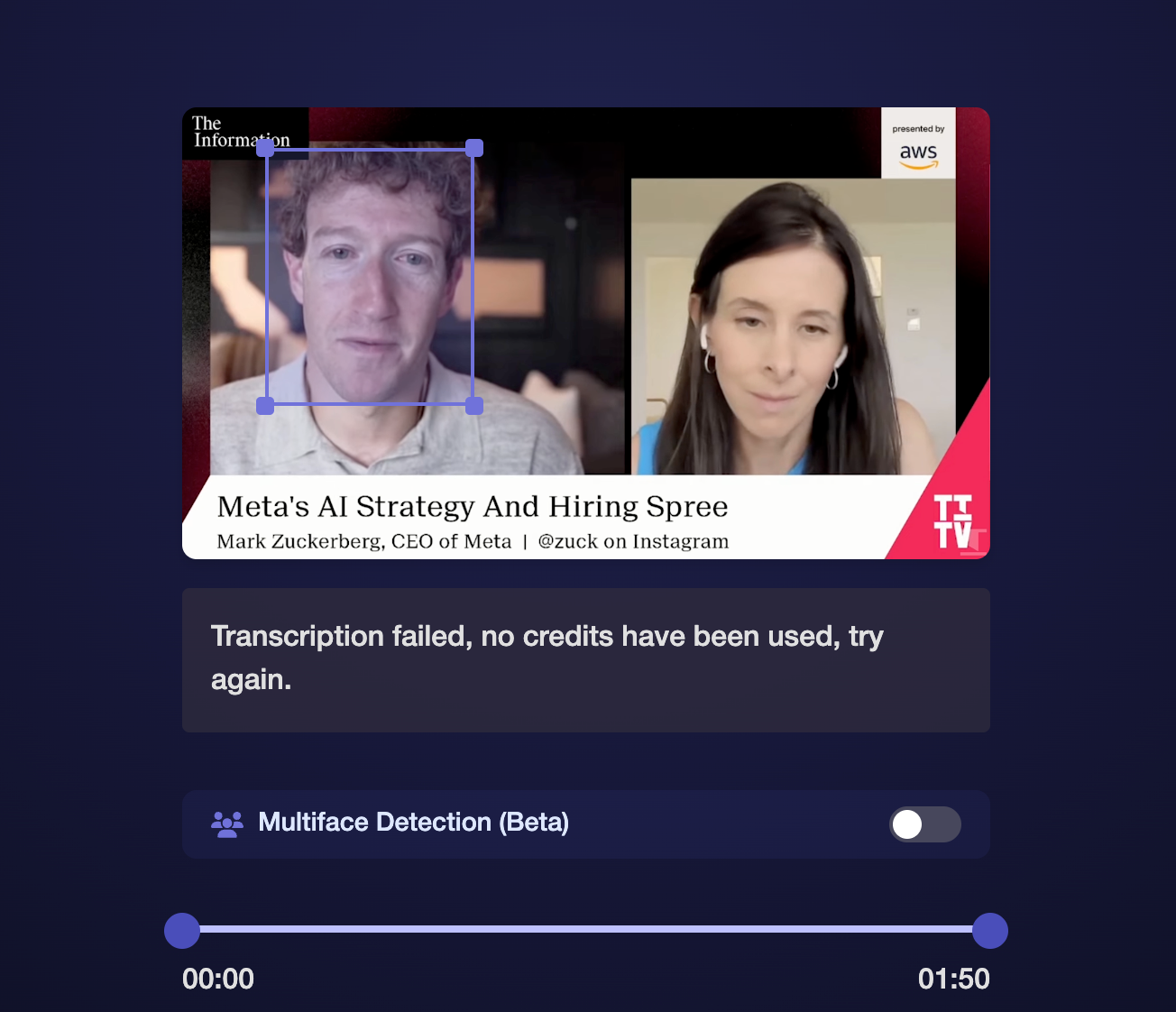
Finally, I did what Meta AI told me to do, and tried a bespoke AI lip reading app. I found one called ReadTheirLips.com, which is powered by Symphonic Labs. This is a tool that people have been trying to use in recent months to figure out what Donald Trump and Jeffrey Epstein were saying to each other in silent b-roll news footage, without much success.
I paid $10 for three minutes worth of transcription and asked it to lip read using its “Multiface Detection.” After waiting 10 minutes, I got an error message that said “Transcription failed, no credits have been used, try again later.” I then asked it to focus only on Zuckerberg, and actually got some text. I separately asked it to focus on Lessin.
Here is a transcript of what the AI says they were talking about. It has not been edited for clarity and I have no idea which parts, if any, are accurate:
LESSIN: Thanks for joining us again, TV. We're happy to have you already this morning. News that you've spent even more money with your big announcement about your new supercomputers. We'll get to that, but to start, you've been in huge scale like I.
ZUCKERBERG: Happy TO BE HERE. We're GOING TO TALK A LITTLE BIT ABOUT META'S AI STRATEGY. It's BEEN BUSY, YOU KNOW? I THINK THE MOST EXCITING THING THIS YEAR IS THAT WE'RE STARTING TO SEE EARLY GLIMPSES OF SELF-IMPROVEMENT WITH THE MODELS, WHICH MEANS THAT DEVELOPING SUPERINTELLIGENCE IS NOW.
LESSIN: You HAVE BEEN ON A PLANE OF AI HIRING, WHY AND WHY NOW?
ZUCKERBERG: Insight, and we just want to make sure that we really strengthen the effort as much as possible to go for it. Our mission with a lab is to deliver personal superintelligence to everyone in the world, so that way, you know, we can put that power in every individual's hand. I'm really excited about it.
LESSIN: I DON'T KNOW, I DON'T KNOW, I DON'T KNOW.
ZUCKERBERG: Than ONE OF THE OTHER LABS YOU'RE DOING, AND YOU KNOW MY VIEW IS THAT THIS IS GOING TO BE SOMETHING THAT IS THE MOST IMPORTANT TECHNOLOGY IN OUR LIVES. IT'S GOING TO UNDERPIN HOW WE DEVELOP EVERYTHING AND THE COMPANY, AND IT'S GOING TO AFFECT SOCIETY VERY WISELY. SO WE JUST WANT TO MAKE SURE WE GET THE BEST FOCUS.
LESSIN: Did YOU FEEL LIKE YOU WERE BEHIND WHAT WAS COMING OUT OF LAW BEFORE I'M NOT ADJUSTING.
ZUCKERBERG: On THIS FROM ENTREPRENEURS TO RESEARCHERS TO ENGINEERS WORKING ON THIS HIDDEN INFRASTRUCTURE, AND THEN OF COURSE WE WANT TO BACK IT UP WITH JUST AN ABSOLUTELY MASSIVE AMOUNT OF COMPUTER RESEARCH, WHICH WE CAN SUPPORT BECAUSE WE HAVE A VERY STRONG BUSINESS MODEL THAT THROWS OFF A LOT OF CAPITAL. LET'S TALK ABOUT.
LESSIN: Like THIS SUMMER, PARTICULARLY, YOU SWITCH GEARS A LITTLE BIT.
ZUCKERBERG: I THINK THE FIELD IS ACCELERATING, YOU KNOW, WE KEEP ON TRACK FOR WHERE WE WANT TO BE, AND THE FIELD KEEPS US MOVING FORWARD.
The video ends there, and it cuts back to the studio.
Update: The Information provided 404 Media with several clips (with audio) from Lessin's interview with Zuckerberg, as well as a real transcript of the interview. Here is the real segment of what was said. As you can see, the AI captured the jist of this portion of the interview, and actually did not do too bad:
Lessin: Mark, thanks for joining TITV. We're happy to have you here. Already this morning, [there’s] news that you've spent even more money with your big announcement about your new supercomputers. We'll get to that. But to start, you took a huge stake in ScaleAI. You have been on a blitz of AI hiring. Why, and why now?Zuckerberg: Yeah, it's been busy. You know, I think the most exciting thing this year is that we're starting to see early glimpses of self-improvement with the models, which means that developing super intelligence is now in sight, and we just want to make sure that we really strengthen the effort as much as possible to go for it. Our mission with the lab is to deliver personal super intelligence to everyone in the world, so that way we can put that power in every individual's hand. And I'm really excited about it. It's a different thing than what the other labs are doing.And my view is that this is going to be something that is the most important technology in our lives. It's going to underpin how we develop everything at the company, and it's going to affect society very widely. So we just want to make sure that we get the best folks to work on this, from entrepreneurs to researchers to engineers working on the data and infrastructure.And then, of course, we want to back up with just an absolutely massive amount of compute which we can support, because we have a very strong business model that throws off a lot of capital.Lessin: Did you feel like you were behind coming out of Llama 4? It seems like this summer, in particular, you switched gears a little bit.Zuckerberg: I think the field is accelerating, you know, we keep on having goals for where we want to be. And then the field keeps on moving faster than we expect.
The rest of the interview is available at The Information.
From 404 Media via this RSS feed


 A page from 'An exploratory study of topographical signatures within 3D fused deposition modelling using Polylactic Acid (PLA) filament.'
A page from 'An exploratory study of topographical signatures within 3D fused deposition modelling using Polylactic Acid (PLA) filament.'