this post was submitted on 19 Jul 2023
409 points (100.0% liked)
Technology
74528 readers
3750 users here now
This is a most excellent place for technology news and articles.
{kind=link}
Our Rules
- Follow the lemmy.world rules.
- Only tech related news or articles.
- Be excellent to each other!
- Mod approved content bots can post up to 10 articles per day.
- Threads asking for personal tech support may be deleted.
- Politics threads may be removed.
- No memes allowed as posts, OK to post as comments.
- Only approved bots from the list below, this includes using AI responses and summaries. To ask if your bot can be added please contact a mod.
- Check for duplicates before posting, duplicates may be removed
- Accounts 7 days and younger will have their posts automatically removed.
Approved Bots
founded 2 years ago
MODERATORS
you are viewing a single comment's thread
view the rest of the comments
view the rest of the comments
I asked for a list of words, and asked to remove any words ending in the letter a. It couldn't do it. I could fight my way there, but the next revision added some back.
This weakness in ChatGPT and its siblings isn't surprising when viewed in light of how these large language models work. They don't actually "see" the things we type as a string of characters. Instead, there's an intermediate step where what we type gets turned into "tokens." Tokens are basically numbers that index words in a giant dictionary that the LLM knows. So if I type "How do you spell apple?" It gets turned into [2437, 466, 345, 4822, 17180, 30]. The "17180" in there is the token ID for "apple." Note that that token is for "apple" with a lower case; the token for "Apple" is "16108". The LLM "knows" that 17180 and 16108 usually mean the same thing, but that 16108 is generally used at the beginning of a sentence or when referring to the computer company. It doesn't inherently know how they're actually spelled or capitalized unless there was information in its training data about that.
You can play around with OpenAI's tokenizer here to see more of this sort of thing. Click the "show example" button for some illustrative text, using the "text" view at the bottom instead of "token id" to see how it gets chopped up.
For that to work, it would need to create a Python script that would remove all of the words ending with A, run that script, and then give you the results. I think this process of handling user requests is in the works.
It would not HAVE to do that, it just is much harder to get it to happen reliably through attention, but it's not impossible. But offloading deterministic tasks like this to typical software that can deal with them better than an LLM is obviously a much better solution.
But this solution isn't "in the works", it's usable right now.
Working without python:
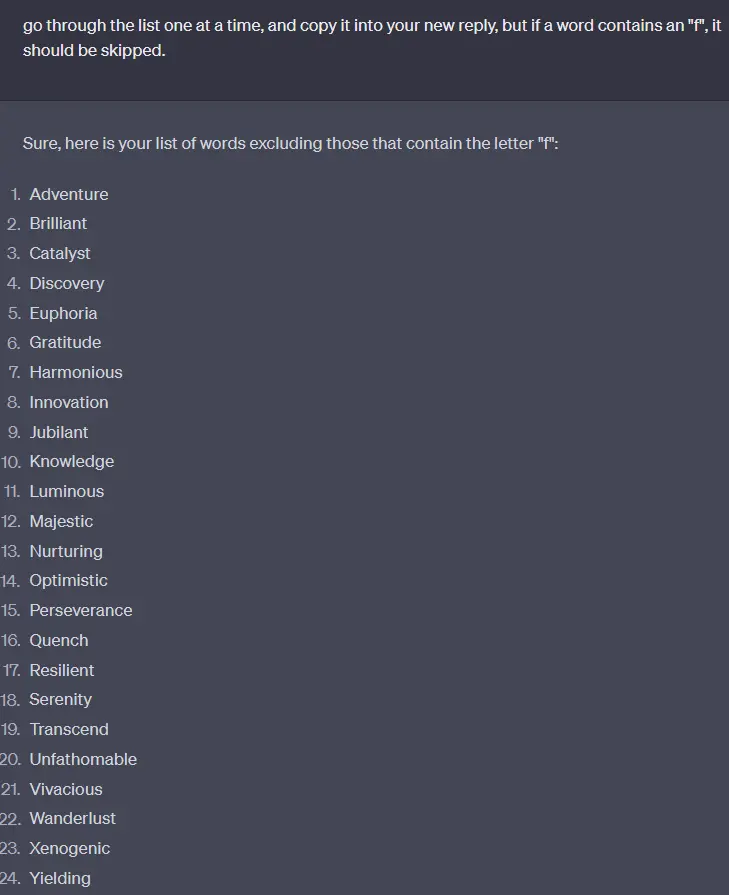
It left out the only word with an f, flourish. (just kidding, it left in unfathomable. Again... less reliable.)