{kind=link}
https://chrome.google.com/webstore/detail/wayback-machine/fpnmgdkabkmnadcjpehmlllkndpkmiak
https://addons.mozilla.org/en-CA/firefox/addon/wayback-machine_new/
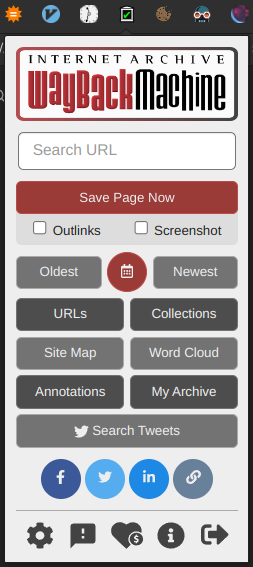
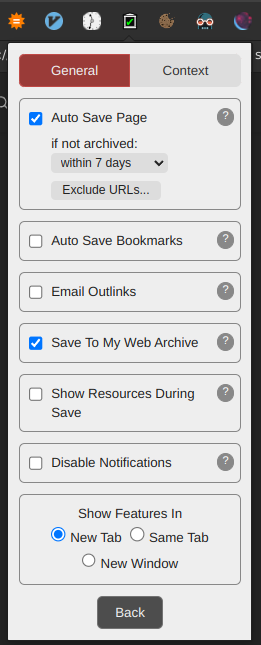
It will also detect when a webpage you are trying to visit is dead and will offer to replay an archived version
