Thanks, that's exactly what I'm looking for.
Ah I thought it was all one file, and maybe that would just be like, commenting out the system section or something.
But I do mean, which apps are installed, what desktop environment, really the user interface, the end user experience that's what I was wondering.
So is there such a repository or not ? Is every nixos user making the configuration file from scratch in vim ?
I figured there should be a repository where most user just pick a ready made file and that's the end of that. Not really having to learn the syntax of that file and writing it down ?
Probably yes !
I meant the file that decides how everything works
I figured if you sent me that file from your system, I'd get your system exactly how you designed it.
I think it would be great to just load random ones of these from other people to see how they like their system.
And then I could pick and choose those aspects that I like while also trying many, radically different ways of doing things as fast as my system can reboot !
You'd be surprised, many humans have simply no backbone, common sense nor self respect so I think they very probably would still, in large numbers. Proof is facebook and palantir.
Because capitalism (and religion before it) told us it would come in the future. As long as we worked as hard as possible in the present.
In the case of religion, this was after you died, until people figured out it was a little too convenient, a little too much of a blank cheque that leaves very little room for recourse if it doesn't turn out as advertised.
In capitalism, "defferred gratification" is sold as a virtue, a sign of good moral character, you are made responsible for your own happiness in a way that requires continual vigilence.
Yes, I find it baffling that this does not yet exist. I was installing debian the other day and the incessant one-question-at-a-time installation with long delays between the question was aggravating. In particular since none of these questions really needed to be answered at the time.
Proxmox does it better, but still with annoying questions and limitation like having a mandatory static IP address and making your enter an email address notification. This is all actually optional stuff and it could all be dealt with after the install is completed.

All firefox really needed to be once google took over everything, was to be a viable alternative and find a way to metabolize all this cash in a way that doesn't damage google's own cash machine or threaten it's actual dominance.
For google the pitance they give firefox is a very cheap insurance policy against against anti-trust legislation. Just like Intel with AMD, this shows how toothless the liberal anti-trust legislation are, even if they were really being enforced, they cannot handle a token 2nd player. It cannot handle controlled opposition if it's credible and believable. So an actual thriving ecosystem doesn't need to exist, we just get duopolies instead of monopolies but in practices we get ducked up the cloaca just the same.
By photo ID, I don't mean just any photo, I mean "photo id" cryptographically signed by the state, certificates checked, database pinged, identity validated, the whole enchilada
If the rendering data for scraper was really the problem Then the solution is simple, just have downloadable dumps of the publicly available information That would be extremely efficient and cost fractions of pennies in monthly bandwidth Plus the data would be far more usable for whatever they are using it for.
The problem is trying to have freely available data, but for the host to maintain the ability to leverage this data later.
I don't think we can have both of these.
If you allow my searchxng search scraper then an AI scraper is indistinguishable.
If you mean, "google and duckduckgo are whitelisted" then lemmy will only be searchable there, those specific whitelisted hosts. And google search index is also an AI scraper bot.
25
For example, let's take the website github.com
If you don't want to have to log in everytime you restart the browser, you have to whitelist the entire website as follows
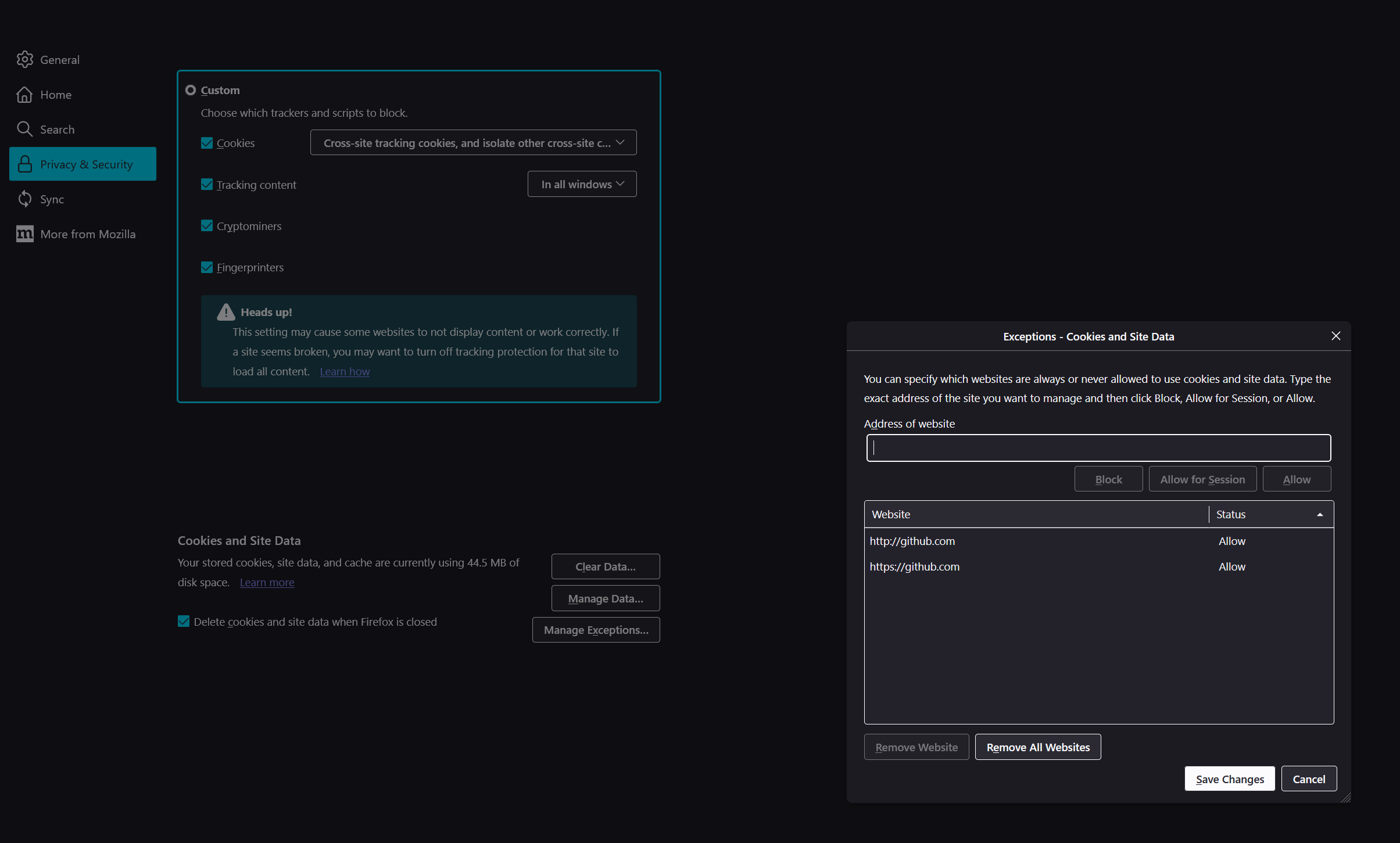
But you would only need to whitelist the following cookies to do so.
on .github.com
logged_in
on github.com
_device_id
user_session
__Host-user_session_same_site
_gh_sess
I found an add-on called "Cookie Quick Manager" which is a great way to consult your cookies on a per-site basis, is container aware, it's great.
In that add-on there was a "protect cookie" function
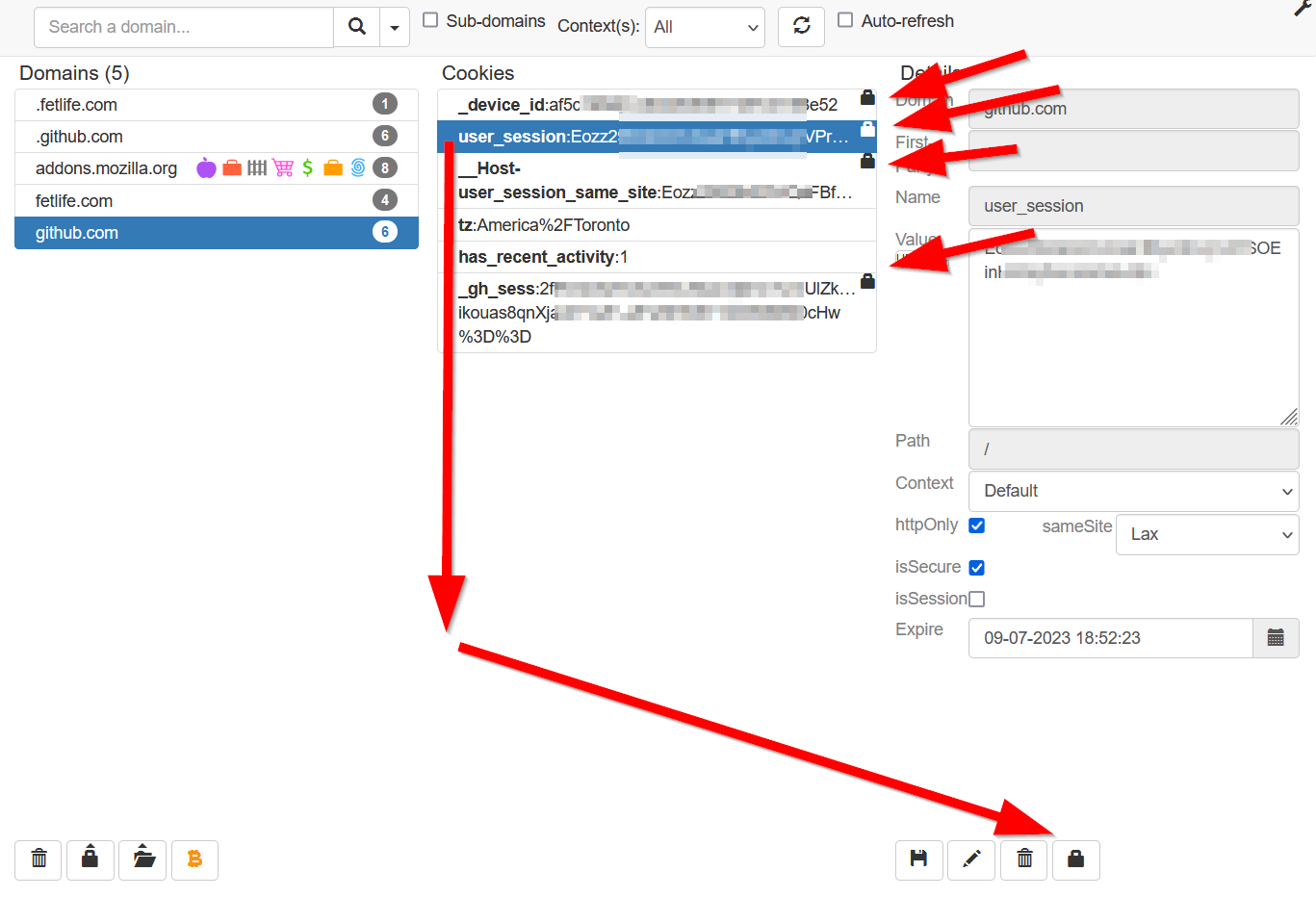
Unfortunately, it would only only protect cookies from getting deleted by "Cookie Quick Manager" and not firefox's "delete data when Firefox is closed" but that would have been a fantastically convenient way to handle this
I think what would make sense would be the ability to append cookie name and container names to the "delete data when Firefox is closed" exception list
So instead of just
You might be able to specify containername!cookiename@https://github.com
With both the containername part and the cookiename part being optional limits to the whitelisting
Here is a mockup of what that might look like


Thanks, although what I'm looking for is a file that will make a kde plasma desktop with chromium and libreoffice installed Something I can plop on a usb stick and hand to grandma so she can linux up her obsoleted win10 pc without me having to explain what a nixos is.
I understand she probably will not understand the nuance of a immutable filesystem based os but that's fine. I simply do not have the energy to tailor a file for each individual grandma that I have.