this post was submitted on 02 Aug 2024
1522 points (98.4% liked)
Science Memes
11148 readers
3713 users here now
Welcome to c/science_memes @ Mander.xyz!
A place for majestic STEMLORD peacocking, as well as memes about the realities of working in a lab.

Rules
- Don't throw mud. Behave like an intellectual and remember the human.
- Keep it rooted (on topic).
- No spam.
- Infographics welcome, get schooled.
This is a science community. We use the Dawkins definition of meme.
Research Committee
Other Mander Communities
Science and Research
Biology and Life Sciences
- !abiogenesis@mander.xyz
- !animal-behavior@mander.xyz
- !anthropology@mander.xyz
- !arachnology@mander.xyz
- !balconygardening@slrpnk.net
- !biodiversity@mander.xyz
- !biology@mander.xyz
- !biophysics@mander.xyz
- !botany@mander.xyz
- !ecology@mander.xyz
- !entomology@mander.xyz
- !fermentation@mander.xyz
- !herpetology@mander.xyz
- !houseplants@mander.xyz
- !medicine@mander.xyz
- !microscopy@mander.xyz
- !mycology@mander.xyz
- !nudibranchs@mander.xyz
- !nutrition@mander.xyz
- !palaeoecology@mander.xyz
- !palaeontology@mander.xyz
- !photosynthesis@mander.xyz
- !plantid@mander.xyz
- !plants@mander.xyz
- !reptiles and amphibians@mander.xyz
Physical Sciences
- !astronomy@mander.xyz
- !chemistry@mander.xyz
- !earthscience@mander.xyz
- !geography@mander.xyz
- !geospatial@mander.xyz
- !nuclear@mander.xyz
- !physics@mander.xyz
- !quantum-computing@mander.xyz
- !spectroscopy@mander.xyz
Humanities and Social Sciences
Practical and Applied Sciences
- !exercise-and sports-science@mander.xyz
- !gardening@mander.xyz
- !self sufficiency@mander.xyz
- !soilscience@slrpnk.net
- !terrariums@mander.xyz
- !timelapse@mander.xyz
Memes
Miscellaneous
founded 2 years ago
MODERATORS
you are viewing a single comment's thread
view the rest of the comments
view the rest of the comments
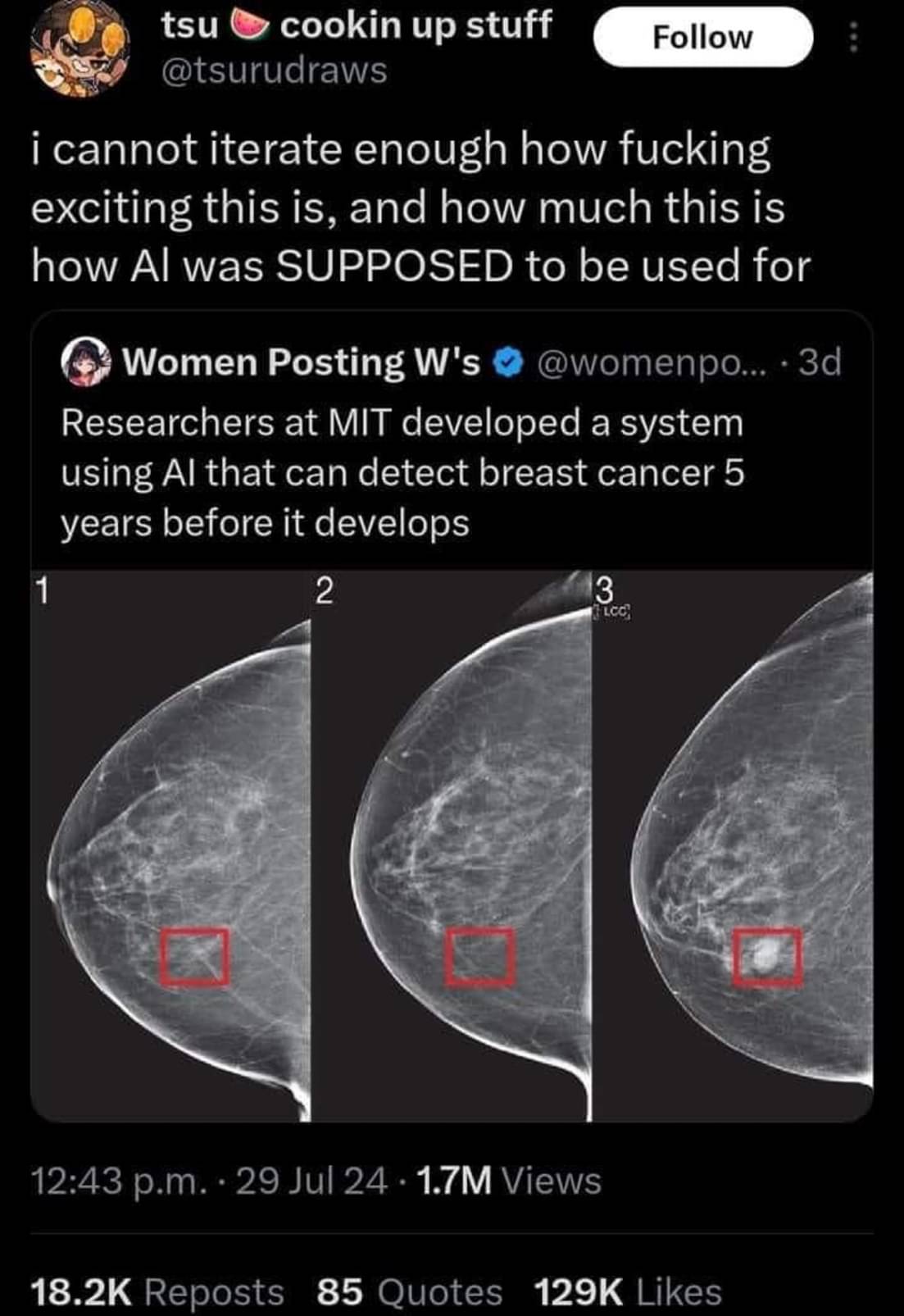
Right, there's typically separate "training" and "validation" sets for a model to train, validate, and iterate on, and then a totally separate "test" dataset that measures how effective the model is on similar data that it wasn't trained on.
If the model gets good results on the validation dataset but less good on the test dataset, that typically means that it's "over fit". Essentially the model started memorizing frivolous details specific to the validation set that while they do improve evaluation results on that specific dataset, they do nothing or even hurt the results for the testing and other datasets that weren't a part of training. Basically, the model failed to abstract what it's supposed to detect, only managing good results in validation through brute memorization.
I'm not sure if that's quite what's happening in maven's description though. If it's real my initial thoughts are an unrepresentative dataset + failing to reach high accuracy to begin with. I buy that there's a correlation between machine specs and positive cases, but I'm sure it's not a perfect correlation. Like maven said, old areas get new machines sometimes. If the models accuracy was never high to begin with, that correlation may just be the models best guess. Even though I'm sure that it would always take machine specs into account as long as they're part of the dataset, if actual symptoms correlate more strongly to positive diagnoses than machine specs do, then I'd expect the model to evaluate primarily on symptoms, and thus be more accurate. Sorry this got longer than I wanted
It's no problem to have a longer description if you want to get nuance. I think that's a good description and fair assumptions. Reality is rarely as black and white as reddit/lemmy wants it to be.