"We believe in an open internet... as long as you use these specific services."
This really sucks. So we're looking at a future where search engines are like streaming services now. "Hmmm now which search engine was on?"
A nice place to discuss rumors, happenings, innovations, and challenges in the technology sphere. We also welcome discussions on the intersections of technology and society. If it’s technological news or discussion of technology, it probably belongs here.
Remember the overriding ethos on Beehaw: Be(e) Nice. Each user you encounter here is a person, and should be treated with kindness (even if they’re wrong, or use a Linux distro you don’t like). Personal attacks will not be tolerated.
Subcommunities on Beehaw:
This community's icon was made by Aaron Schneider, under the CC-BY-NC-SA 4.0 license.
"We believe in an open internet... as long as you use these specific services."
This really sucks. So we're looking at a future where search engines are like streaming services now. "Hmmm now which search engine was on?"
That's why I use a SearXng instance. Why bother searching for something on 1 instance when you could search for it on 5 and then correlate the results.
Are we looking at a future where we need a search engine to tell us which search engine to use for your queries?
I think we’re looking at a future where Google ensures we don’t ever have to worry about making such a choice.
Microsoft is working very hard at getting into this data game. Don't think they won't try making similar deals.
The more players capable of making such deals, the less valuable such deals become. So I saw go for it Microsoft and I hope the landscape gets further and further fractured to the point where exclusivity deals don’t work out for the sites.
No, don't worry. The AI will pick one for us.
Oh boy, I can't wait to see what has already happened to streaming services happen to search engines!
I don’t have a ton of knowledge in this area, but this seems like it should run afoul of antitrust regulations?
That was my first thought too. Yet another reason to vote for Dems this November - only one party actually gives a shit about enforcing antitrust regulations!
are you absolutely positive the democrats give a shit about antitrust regulations? Biden did actively strike break.
This is true, and it was a black mark against his record in my mind. But antitrust is not the same thing as pro-worker.
He did at the beginning, but he helped them get what they wanted in the end, and I think that counts for something.
“We’re thankful that the Biden administration played the long game on sick days and stuck with us for months after Congress imposed our updated national agreement,” Russo said. “Without making a big show of it, Joe Biden and members of his administration in the Transportation and Labor departments have been working continuously to get guaranteed paid sick days for all railroad workers.
“We know that many of our members weren’t happy with our original agreement,” Russo said, “but through it all, we had faith that our friends in the White House and Congress would keep up the pressure on our railroad employers to get us the sick day benefits we deserve. Until we negotiated these new individual agreements with these carriers, an IBEW member who called out sick was not compensated.”
Oh yeah you're right we should just not even bother voting and let the right wing win.
Where did I say that? Of course we should vote blue. But let's not delude ourselves into thinking they already agree with us on issues we're going to have to protest for.
Who should be regulated, Google or Reddit? Reddit updated there robots.txt to disallow everything. As it's their site, I guess it's also their right to determine that. They then made a deal with Google, which I guess is also not abusing a dominant position by Google, as Reddit could have made a deal with anyone.
Yeah but reddit made a deal with google because google’s the big player.
It’s hard to say, but I’d lead toward Google on this one. How does reddit benefit from only being indexed by one search engine? Google must have offered them something more, to make it in reddit’s best interests.
In other words, this deal naturally benefits only google, at the cost of value to reddit and to the public. So google must be doing something that makes it worth it to reddit. Could be threat of punishment: “You give us exclusive crawl access, or we don’t crawl you”.
In 2023, Reddit decided to start charging exorbitant amounts for API access, making it non-viable for free 3rd party apps to access its content, citing things like AI crawlers "stealing" their (users') content.
In 2024, Google announced an agreement with Reddit to access the API, citing things like enhanced up to date search results. I don't recall having seen whether they pay for it, or how much, but possibly they do.
It would stand to reason, that if Reddit has managed to get a single dime for API access, and they keep thinking free access to their users' content is "stealing", then Reddit would be interested in making it as hard as possible to access the content without paying.
Could be threat of punishment: “You give us exclusive crawl access, or we don’t crawl you”.
That could've been part of the agreement: "You give us cheap/free API access, or we don't crawl you".
Reddit tightening things down while trying to sell API access, just happens to benefit Google.
Given lawmakers that understand how the internet works, I think it would be. To me this isn't any different than a handful of years back when ISPs were throttling websites to give an advantage to the certain ones that paid them to work faster.
Reddit search, notorious for being shit, has upgraded to a top tier shit pile.
If you use Bing, DuckDuckGo, Mojeek, Qwant or any other alternative search engine that doesn’t rely on Google’s indexing and search Reddit by using “site:reddit.com,” you will not see any results from the last week. DuckDuckGo is currently turning up seven links when searching Reddit, but provides no data on where the links go or why, instead only saying that “We would like to show you a description here but the site won't allow us.” Older results will still show up, but these search engines are no longer able to “crawl” Reddit, meaning that Google is the only search engine that will turn up results from Reddit going forward.
Can anyone confirm this? I typically use DDG, and I tried verifying this, but i'm not sure what to search on reddit that would exclusively bring up results from the past week. Seems like most of the time I'm reading posts from a year ago or more anyway, so it's hard to see the effect immediately.
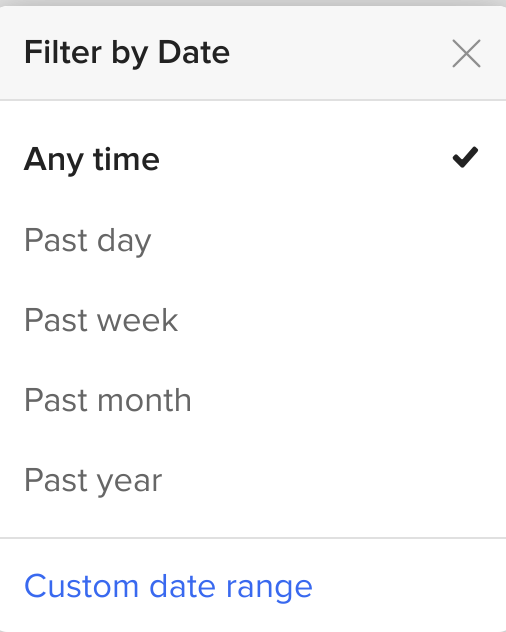
aha. yeah that does it. i guess i never used that previously, so i have no comparison point for how well it worked before this deal. But sure enough, i get no results when searching very generic terms and filter to just the last week.
I'm just getting the Jimmy Carter and Trans wiki pages regardless of what I search for, regardless of which browser I use lol. I mean, not irrelevant to me but not super helpful.
Firefox
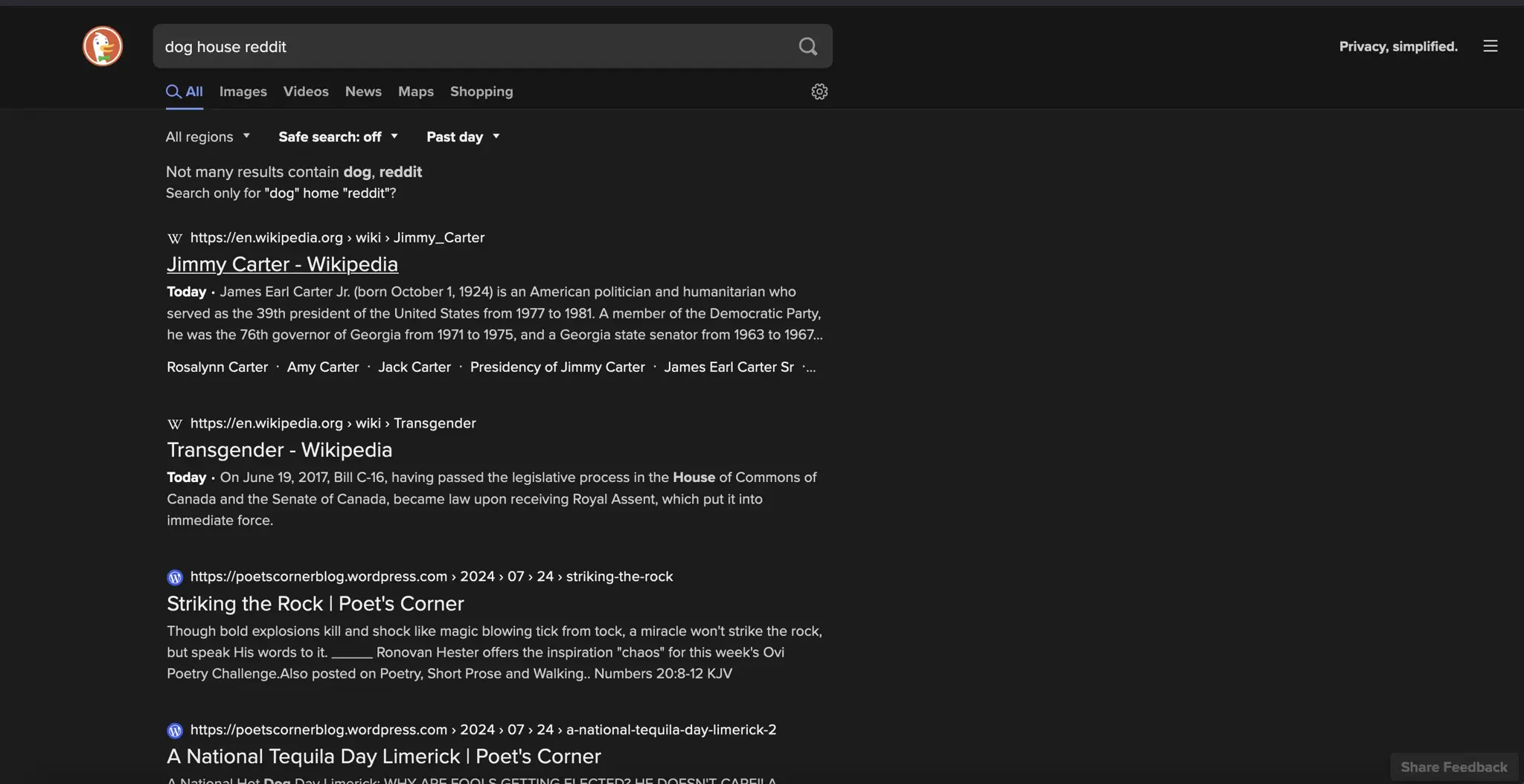
Chrome (Private)
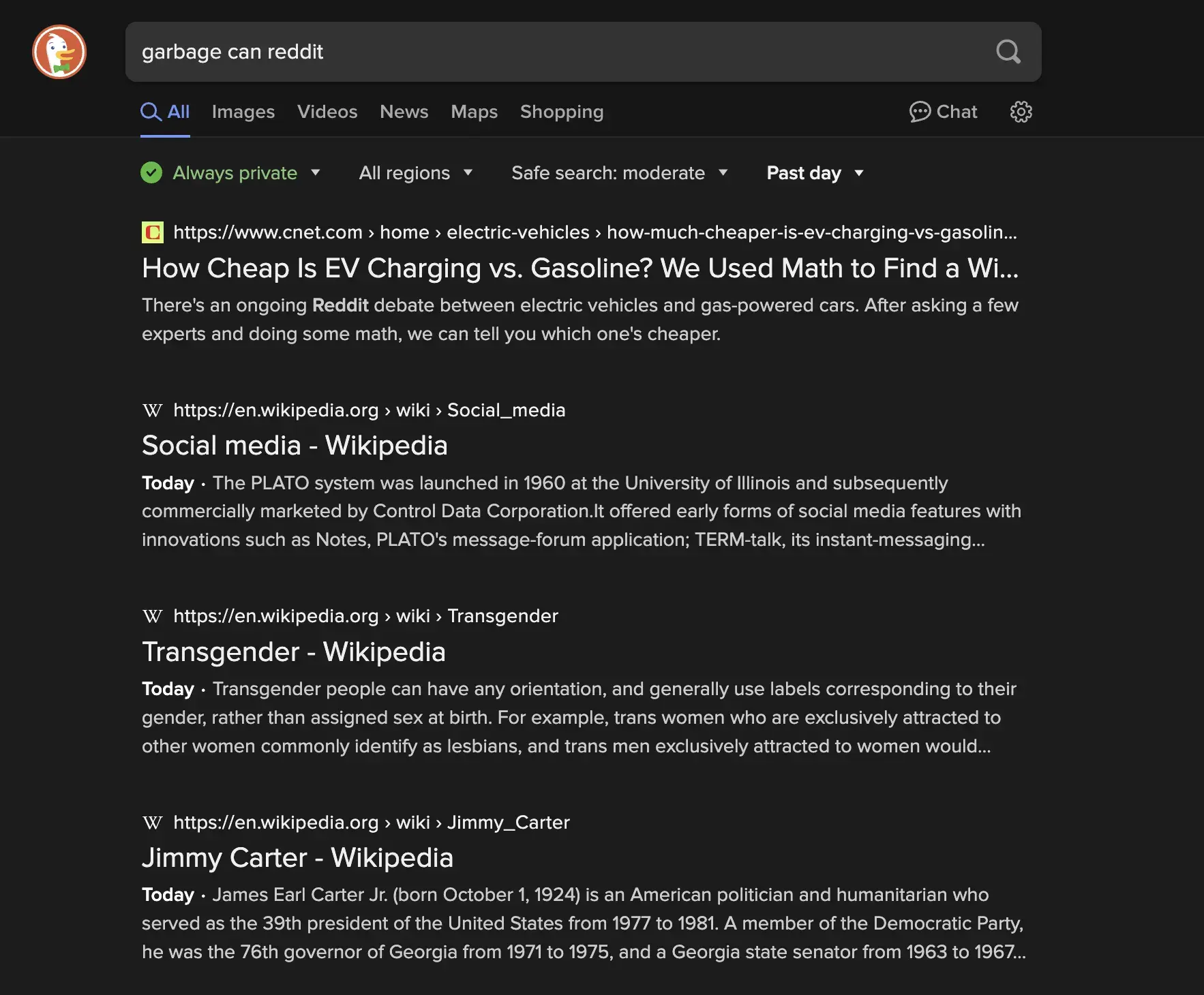
hello, we're quoted in the piece, set your parameters to look only since the change/recently i.e.
Bing - Restricted to a week here and there is nothing
Mojeek - We are not crawling due to the block, avoiding adding results without content
As most are just using Bing's results (DDG, Qwant, Ecosia) you should see similar.
Trump assassination attempt, Biden dropping out of presidential race
Does this mean the Internet Archive will no longer be archiving reddit posts? That's how I've tried viewing most since I deleted my accounts.
I honestly do not think Internet Archive even should be archiving such behemoths like Reddit or Twitter. Only thing it should keep would be currently dead sites.
Even worse when people are accessing these posts through Archive even when there is a live copy. A lot of storage and bandwidth wasted.
Archives are ideal for identifying sneaky behavior like that. You never know when an admin might have the ability to delete or edit something without anyone noticing.
But imagine this... an immoral rich human being, who's family got rich by mining blood rubies in south Africa, buys reddit for 50B$. This person fires half the people and refuses to pay the bills for servers and the servers shut down... how will you access your favorite GoneWild posts? This is all fictional of course.
...but at some point those giant sites may go offline. I see the point of archiving them now for posterity, but you're right. The archive shouldn't be used as a concurrent mirror of those sites for privacy reasons.
I have my browser set up to redirect Reddit links to libreddit instances for that purpose.
How do you keep a currently dead website you did not previously archive?
True, although I think there usually are either signs or site admins give heads up when site is soon to go under. Doubt Reddit or Twitter will be dead any time soon.
We need to do something to protect Internet Archive and its access to scrape sites.
Ummmmmmmm. This seems illegal. Is this not illegal?
It's a bit of a dilemma reading their policy:
We believe in the open internet and in keeping Reddit publicly accessible to foster human learning (...) Unfortunately, we see more and more entities using unauthorized access (...) especially with the rise of use cases like generative AI. This sort of misuse of public data has become more prominent as more and more platforms close themselves off from the open internet.
We still believe in an open internet, but we do not believe that third parties have a right to misuse public content just because it’s public.
Being a open/public platform, but still wanting to protect user's content from being used for AI could be a good thing, and I guess also what many fediverse users would want for this platform. Making a distinction between AI and search indexing could indeed be difficult. But then making content deals with Google for search indexing and AI training is a bit hypocrite.
We still believe in an open internet, but we do not believe that third parties have a right to misuse public content just because it’s public.
You need to pay us for the right to misuse our site's data!
I still don’t buy that protecting people’s content from being read by AI is a good thing. I think the fear of AI stealing our thunder or whatever by reading what we’ve written is overblown as a fear.
It's not a big deal... for now, because most of the time when I limit DDG results I ask for 1 year back (for solutions that are sort of recent but not ancient).
I would never limit results to just the last week, and typically posts that are that fresh won't have enough accumulated knowledge so even if they pop up on the results they're not really useful.
Again, that's just my experience. I'm curious if others have similar ones.
In 51 weeks, the decreasing usefulness of that search drops to zero. This is not about now; it's about the future.
And that comment is not about “what it’s about”. It’s about being curious. It’s incidental to the topic at hand.
True but It will become a bigger deal every passing day that is the problem.
I also wonder if search engine's will delist results after a period of time. If the site is blocking them. After all you don't want your top results to just be 404s all of the time.