519
It's fascinating that while languages vary wildly by speaking speed, information transfer is fairly similar.
(lemmy.world)
A place to share and discuss visual representations of data: Graphs, charts, maps, etc.
DataIsBeautiful is for visualizations that effectively convey information. Aesthetics are an important part of information visualization, but pretty pictures are not the sole aim of this subreddit.
A place to share and discuss visual representations of data: Graphs, charts, maps, etc.
A post must be (or contain) a qualifying data visualization.
Directly link to the original source article of the visualization
Original source article doesn't mean the original source image. Link to the full page of the source article as a link-type submission.
If you made the visualization yourself, tag it as [OC]
[OC] posts must state the data source(s) and tool(s) used in the first top-level comment on their submission.
DO NOT claim "[OC]" for diagrams that are not yours.
All diagrams must have at least one computer generated element.
No reposts of popular posts within 1 month.
Post titles must describe the data plainly without using sensationalized headlines. Clickbait posts will be removed.
Posts involving American Politics, or contentious topics in American media, are permissible only on Thursdays (ET).
Posts involving Personal Data are permissible only on Mondays (ET).
Please read through our FAQ if you are new to posting on DataIsBeautiful. Commenting Rules
Don't be intentionally rude, ever.
Comments should be constructive and related to the visual presented. Special attention is given to root-level comments.
Short comments and low effort replies are automatically removed.
Hate Speech and dogwhistling are not tolerated and will result in an immediate ban.
Personal attacks and rabble-rousing will be removed.
Moderators reserve discretion when issuing bans for inappropriate comments. Bans are also subject to you forfeiting all of your comments in this community.
Originally r/DataisBeautiful
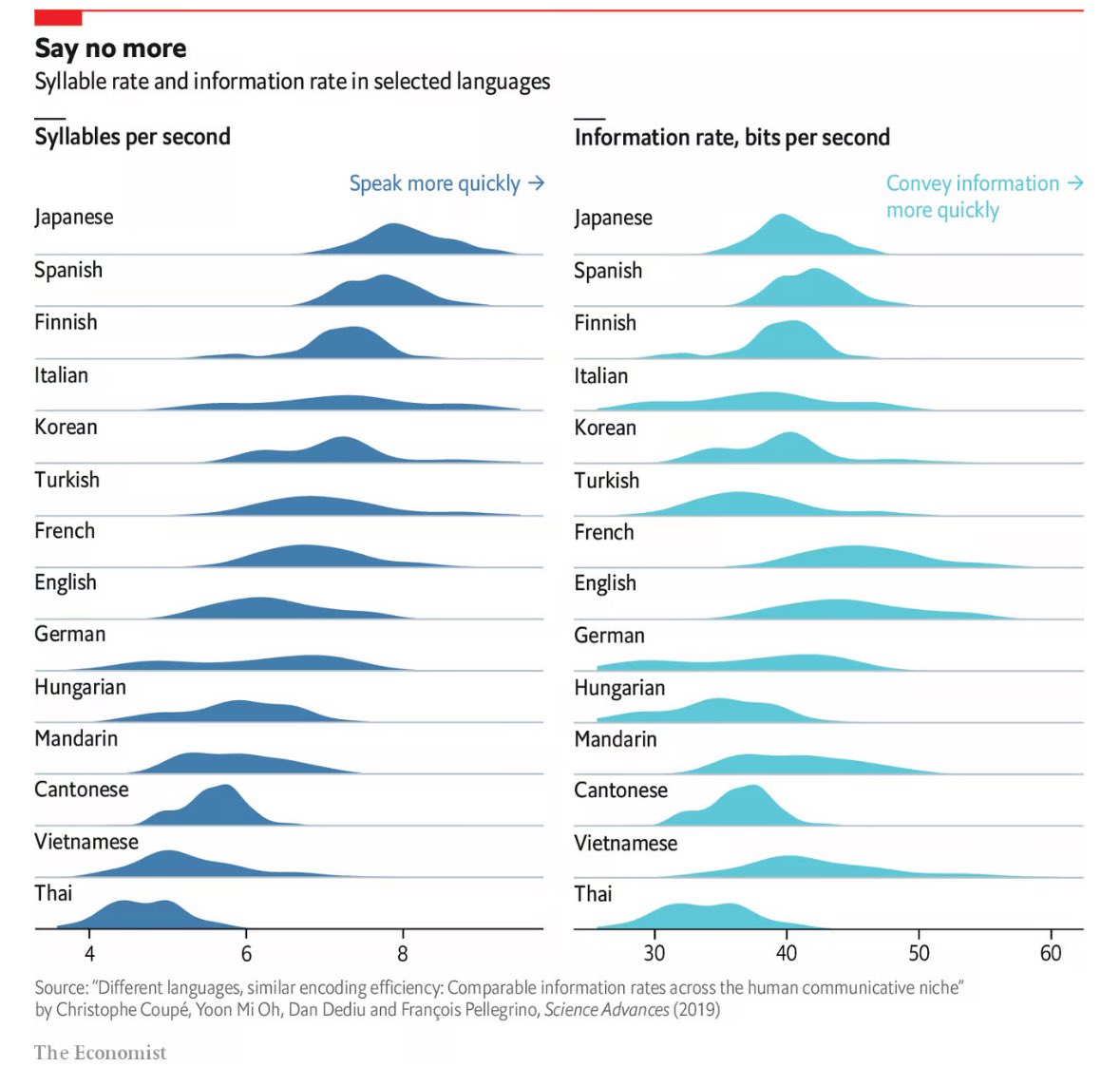
Poor Thai down there at the bottom, speaking slowly and transferring information slowly.
Thai, the PNY USB stick of languages, apparently.
Actually fewer syllables per second is good, means you’re spending less effort speaking. It’s the ratio of information/syllables you want to maximize. Which means German/English/Mandarin/Vietnamese are roughly on par as the most “efficient” languages.
Some languages have fewer vowel sounds while others have an insane number (in Europe that would be Danish).
Thai has a lot, so speakers need to speak more slowly so the listener has time to distinguish words. But it also means that you can have more words per syllable.
It's not about efficiency per se - it's data and error correction
Just to add - Thai has a tonal system and distinguishes rising, low, medium, high and falling tones. This requires a bit more time to say so that there is time for the tone to change (or not change).
LMFAO PNY USB that's poetic
This was one of the weirdest things I had to learn when I was learning spanish. The sounds are much faster but the information density was similar. For me as an english native speaker it felt like I was listening to a machine gun at first. Eventually I trained my ear and now both languages sound the same speed.
This is also why, to me, rapidly spoken natural Spanish and Japanese sound oddly similar if I hear it out of "the corner" of my ear, so to speak.
Which is funny cause I kinda speak Spanish lol
I am pretty skeptical about these results in general. I would like to see the original research paper, but they usually
And then there's the question of how do you measure the amount of information conveyed in natural languages using bits...
Yeah, the results are mostly likely very skewed.
So I did a quick pass through the paper, and I think it's more or less bullshit. To clarify, I think the general conclusion (different languages have similar information densities) is probably fine. But the specific bits/s numbers for each language are pretty much garbage/meaningless.
First of all, speech rates is measured in number of canonical syllables, which is a) unfair to non-syllabic languages (e.g. (arguably) Japanese), b) favours (in terms of speech rate) languages that omit syllables a lot. (like you won't say "probably" in full, you would just say something like "prolly", which still counts as 3 syllables according to this paper).
And the way they calculate bits of information is by counting syllable bigrams, which is just.... dumb and ridiculous.
I take your point without complaint, but I still think you're an alien for saying "prolly"
I mean, probs. It's right there. Use that if you have to
Alright, but dismissing the study as “pretty much bullshit" based on a quick read-through seems like a huge oversimplification. Using canonical syllables as a measure is actually a widely accepted linguistic standard, designed precisely to make fair comparisons across languages with different structures, including languages like Japanese. It’s not about unfairly favoring any language but creating a consistent baseline, especially when looking at large, cross-linguistic patterns.
And on the syllable omission point, like “probably” vs. “prolly," I mean, sure, informal speech varies, but the study is looking at overall trends in speech rate and information density, not individual shortcuts in casual conversation. Those small variations certainly don’t turn the broader findings into bullshit.
As for the bigram approach, it’s a reasonable proxy to capture information density. They’re not trying to recreate every phonological or grammatical nuance; that would be way beyond the scope and would lose sight of the larger picture. Bigrams offer a practical, statistically valid method for comparing across languages without having to delve into the specifics of every syllable sequence in each language.
This isn’t about counting every syllable perfectly but showing that despite vast linguistic diversity, there’s an overarching efficiency in how languages encode information. The study reflects that and uses perfectly acceptable methods to do so.
This conjecture explains the results surprisingly well. If the original was written in French, which then got translated to English, which was then used as the basis of translation for the other languages that would explain the results entirely.
In Finnish, I can simply ask, "Juoksenneltaisiinko?" whereas in English, I have to say, "Should we run around aimlessly?"
Traipse?
That's the full sentence asking if you want to run around aimlessly.
Interesting word, I hadn't heard of that one before. While not exactly perfect translation, it seems like a similar kind of word nevertheless. Doesn't exactly seem to refer to running directly though.
I guess that in the case of my example, it's more of a demonstration of how weirdly Finnish language can work. Juosta = run, juoksennella = run around aimlessly, juoksenneltaisiinko? = should we run around aimlessly?
So if I'm reading this right, French (closely followed by English) tends to convey the most info per unit time?
Yes but they also utilize smell.
As a french, I'm very surprised by this, as when I see a text in French side-by-side with its English translation, the English version is usually shorter. It may be a difference between speech and text, but it's still surprising.
I really thought the information density of French was pretty low, compared to English or Breton, for example.
Written French is slow (needs more words )
Spoken French IS faster
What produces the stretched graphs like Italian and German? What do these humps mean?
Variability in the length of words, loads of very short and very long words? Just a guess
That is likely part of it and also explains why languages like Japanese are more tightly grouped, as there is less spread in word length for Japanese versus English or Italian.
Both of those languages LOVE to compound their nouns - smashing smaller words into massive ones. Like the simple "pasta + asciutta = pastasciutta = dried pasta" or not simple "Donaudampfschifffahrtsgesellschaftskapitän = Danube steamship transport company captain". All languages do it, but these do it with gusto.
Maybe they didn't account for various factors like age or mood.
Moreover, Munic has 130 words per minute and dortmund has 180 words. There's a ddifference in the dialect
https://preply.com/de/blog/sprechtempo-in-deutschland/ the numbers are just estimations and not a hard fact.
My hump my hump my hump, my lovely language lumps.
I would guess, if it's solid empirical work behind this, that there's just greater differences internally between German and Italian speakers than for many other languages. Having lived in both Germany and Italy, I do not struggle to believe this is the case.
Inaccurate for Italian because 50% of the language is conveyed by auditory volume, hand gestures and body language .... and espresso, lots and lots of espresso.
Turkish is also inaccurate because 25% of the language is in the eyes .... those intense eyes where you can't tell if someone is excited, energetic, full of life or psychotic / murderous.
hand gestures
🤌
That's what I mean .... just that hand gesture depending on who made it and in what circumstance just conveys a ton of information without saying a word.
It could mean ... "hey that was fantastic spaghetti and the sauce was wonderful"
Or it could mean .... "that was a ballsy move you did last night ... imma gonna keep my eye on you and burn down your house next week"
As someone who speaks both French and English, I'm surprised to see French as leading "information density" language. Most French terms have been incorporated into English. Language tends to be behind on technology terms. Language doesn't have any noticeable difference in short syllable common words to English. It also seems to me that French speakers have an easier time in being vague. I have the impression that English is more precise.
Looking at the two curves, it looks like they are pretty close but French edges out English because of the speed it's spoken at.
Even when it was fresh in my mind, I was never able to follow French tv because they just go so fast.
Cowards left out Navajo.
Yeah but 30% of the information in French are the "uhhh's" lmao
Speaking of "data is beautiful", IMO a 2D scatter plot would be very useful for visualizing this relationship. This chart does provide the distribution for each language, as opposed to just the average, but at the expense of making correlation (or lack thereof) difficult to see.
Also, the ratio of the largest to the smallest value for syllables per second and for bits per second appears to be fairly similar. I have to eyeball values but it looks like Japanese : Thai is 8.0 : 4.7 for syllables per second (so 1.7) whereas French : Thai is 48 : 34 (so 1.4) for bits per second.
For each language, the distribution of syllable rate looks very much like the distribution of bit rate. I would like to see a chart of bits per syllable. Oh, and I wonder how this affects reading speed and the rate of information transfer via reading, especially for different spoken languages that use similar written characters.
The French/English/German curves are interesting, given the relationships between them.
I wonder if this implies English has more in common with French than German.
Or how the German and Italian curves are so similar, does that reflect a similarity in language or in how it's used (cultural)?
English is vocabulary wise a neolatin language like french. More than 50% of english words are of latin origin, from roman latin to anglo-norman-french to modern french. English has also lost almost all noun declinations present in german and old english, with the exception being the genitive 's like dog's tail), and the plural, that takes an -s suffix (apple apples), which makes it similar to french and neolatin languages. So, there is something to it.
I would imagine this is because there is a 'comfortable' rate of information exchange in human conversation, and so each given language will be spoken at a pace that achieves this comfortable rate.
So it's not that the syllable rate coincidentally results in the same information rate, but the opposite - the syllable rate adjusts to match the desired information rate.
Interesting thought.
I'd add it's probably also that 90%+ of conversation isn't about "data transfer" in the technical sense, but relationship building. So information volume isn't usually crucial.
Now let's see this work done in technical fields, especially change management, maintenance, emergency services, etc, where time is crucial. Those environments tend to have very "coded" language, so we don't have to say a paragraph whenever we call for a very specific function/tool/action.
I suspect the languages would still have similar curves, but the data rates would increase.
I always thought that English was an efficient language.
Wonder how Thai is the zipfile of languages.
It is multiplexed with five tones and a variety of different registers to signify relationship, status, and variable interplay between the two based on situation.
I’d like a visual of how much unnecessary elaboration different languages commonly use to make a point.
Though you can elaborate excessively for fun, how much is common?
And on the other end of the scale text speak is often extremely concise (not me tho ha). Would be cool to see and compare the limits.
Turkish seems inefficient. You spend the effort to talk quickly but don't get the reward of high info transfer speed like Spanish.
The words are very modular and systematic, but you seemingly pay a price for it.